Zaya1 8B is an open-source 8.4 billion parameter Mixture-of-Experts model with only 760 million active parameters per token, trained entirely on AMD hardware, and it posts results that beat some much larger systems on hard math and reasoning.
In head-to-head claims, it outperforms Claude 4.5 Sonnet and Gemini 2.5 Pro on hard evaluations, stays competitive with DeepSeek R1, and even comes close to GPT-5, which is a big statement for a model at this size. The stated goal is simple and it shows in practice: squeeze maximum intelligence out of minimum parameters.
I installed it locally through vLLM on an NVIDIA RTX 6000 48 GB card and tested both math reasoning and coding. It responded quickly and correctly handled multi-step fuel and wind vector math in a realistic aviation emergency prompt, but it produced a wrong course heading, which would be critical in-flight.
It then designed and ran a realtime collaborative code editor using Python and FastAPI that worked exactly as specified across two browser windows with WebSockets and session isolation.
What stands out Zaya1 8B?
Zyphra had a busy run with earlier models like Zonos and ZR1, went quiet for more than a year, and returned with Zaya1 8B. The hallmark here is the training on AMD GPUs at this performance level plus MoE routing that keeps active compute low.
The model shows strong math and coding under pressure while staying light enough to run on a single high-memory GPU.
Benchmarks at a glance
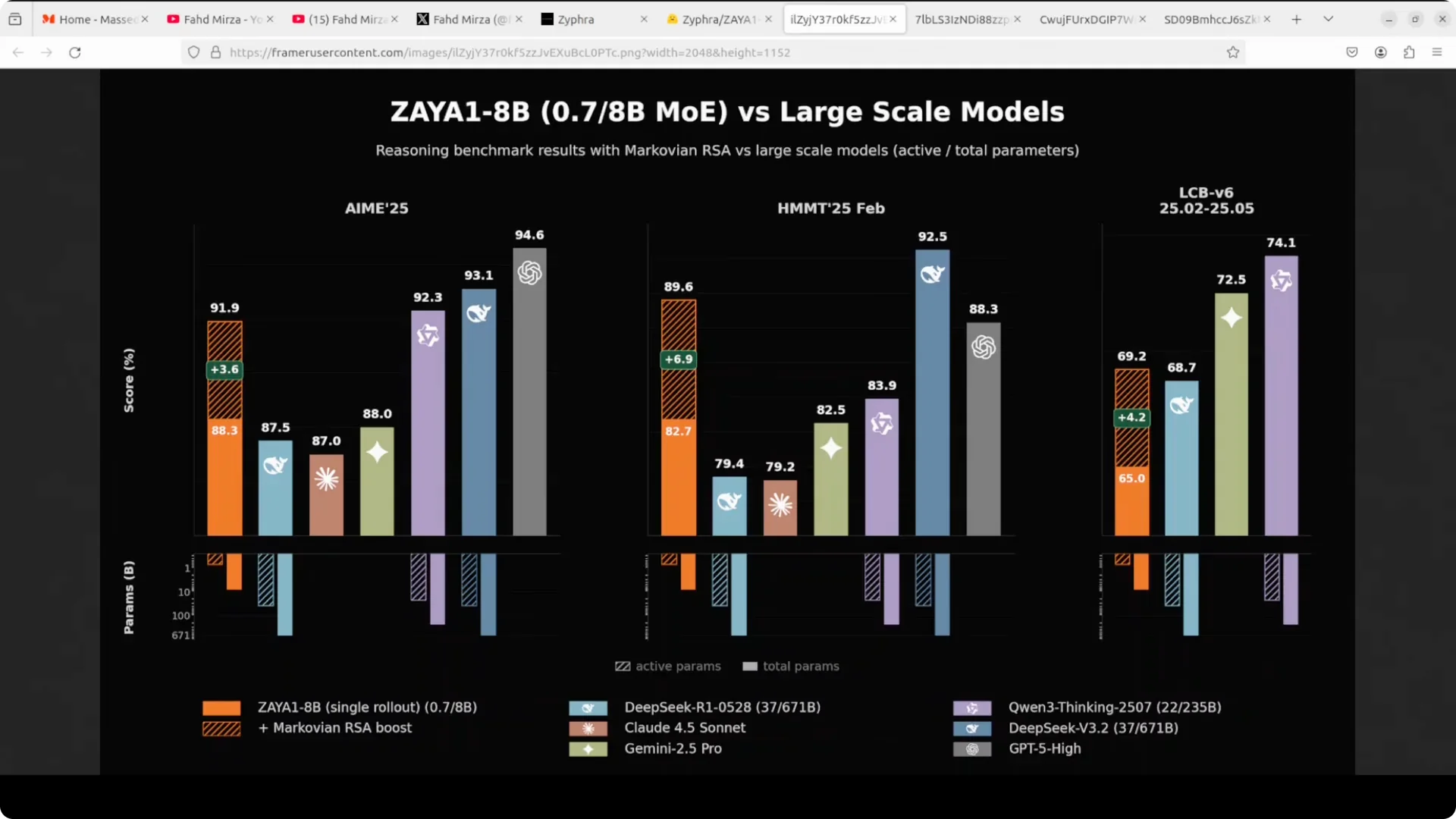
On the large model comparison, Zaya1 8B with its Marovian RSA boost reportedly beats Claude 4.5 Sonnet and Gemini 2.5 Pro on hard tasks.
It remains competitive with DeepSeek R1 and gets close to GPT-5 on select measures.
Against open-source peers, it beats Mistral Small 4 on most tests, while NVIDIA Neotron 3 Nano takes a few tasks.
Architecture in plain words
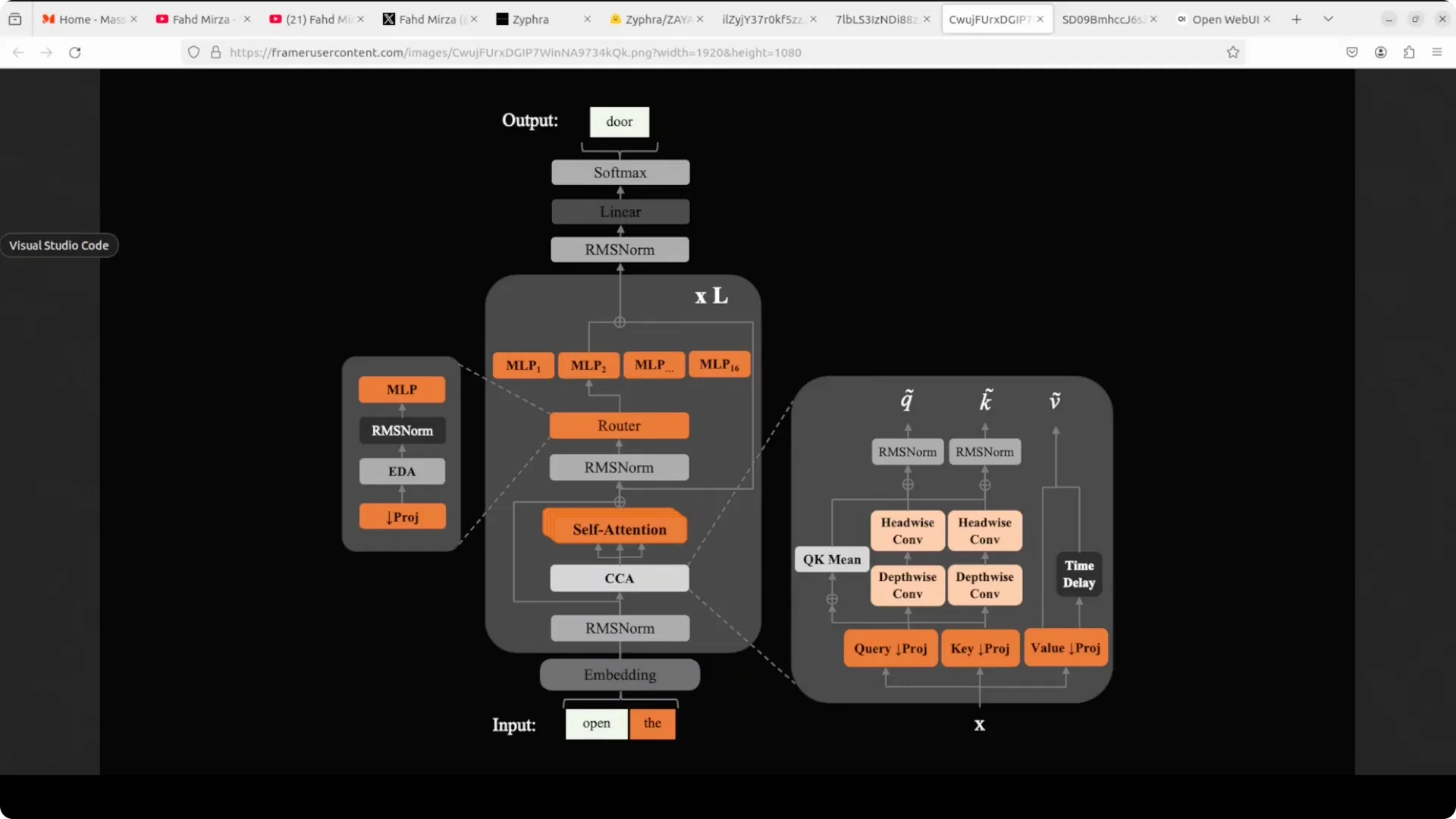
Think of Zaya1 8B as a factory line: text comes in, passes through stacked stations, and a predicted token comes out.
The design focuses on paying attention to the right context and activating only the right specialists. That is how it keeps compute small but impact high.
CCA block
The CCA block is Zyphra’s smarter way for the model to attend to words in context. It improves how the model decides what to focus on without bloating active compute. That attention quality underpins its reasoning strength.
Mixture of experts
A router picks from 16 expert modules for each input instead of lighting up the whole model. Only about 760 million parameters are active at a time out of the 8.4 billion total.
That routing choice is the core trick that keeps speed and memory in check.
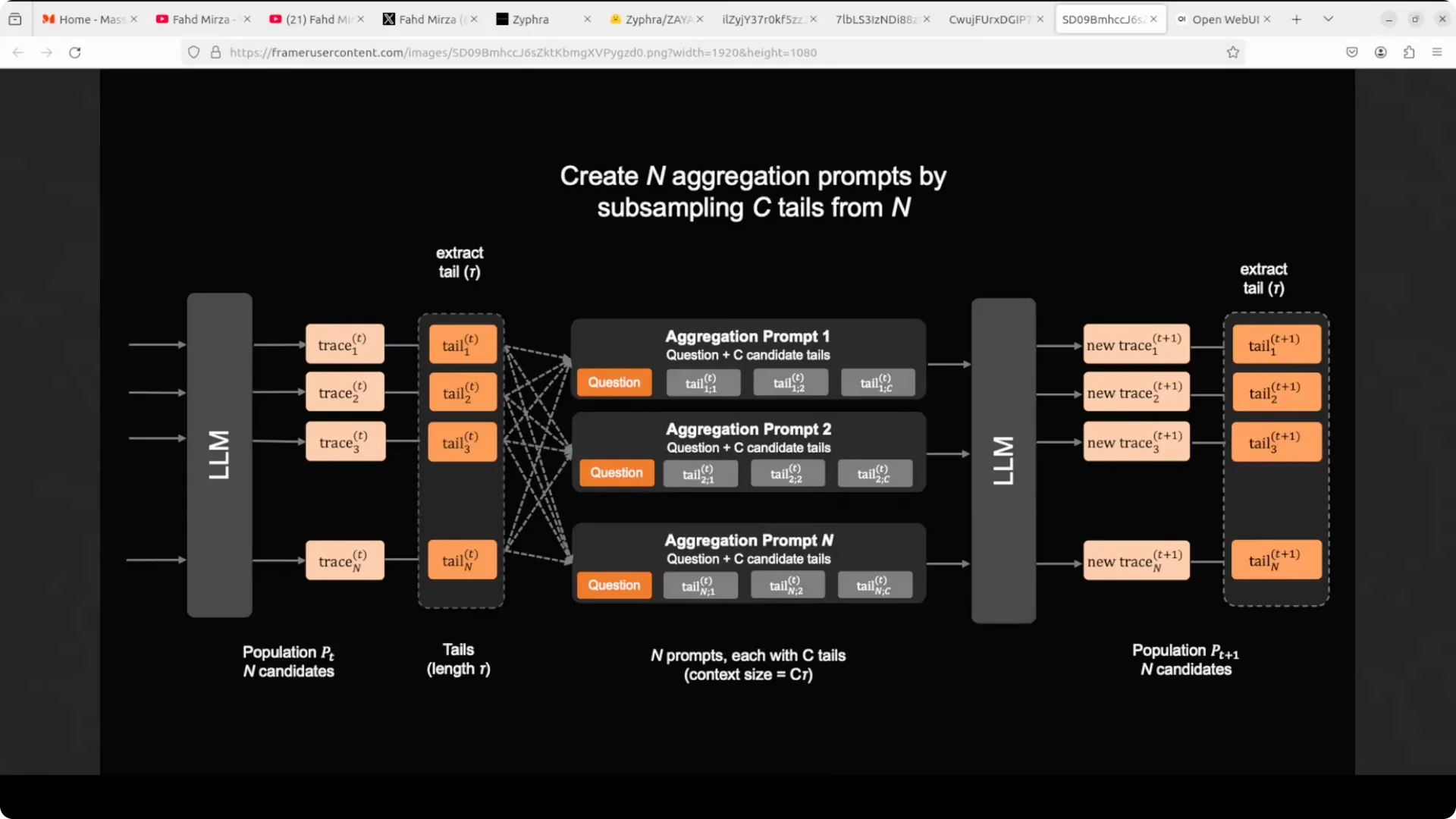
Marovian RSA made simple
Imagine giving a tough math or coding problem to a classroom. Each student works independently, and you keep only their final conclusions.
You then give new students the same question plus a handful of those conclusions as hints, cycle after cycle, and performance climbs without growing the context window because you only carry forward the tail end of each trace.
Read More: drafter setup with Gemma 4
Local install and setup
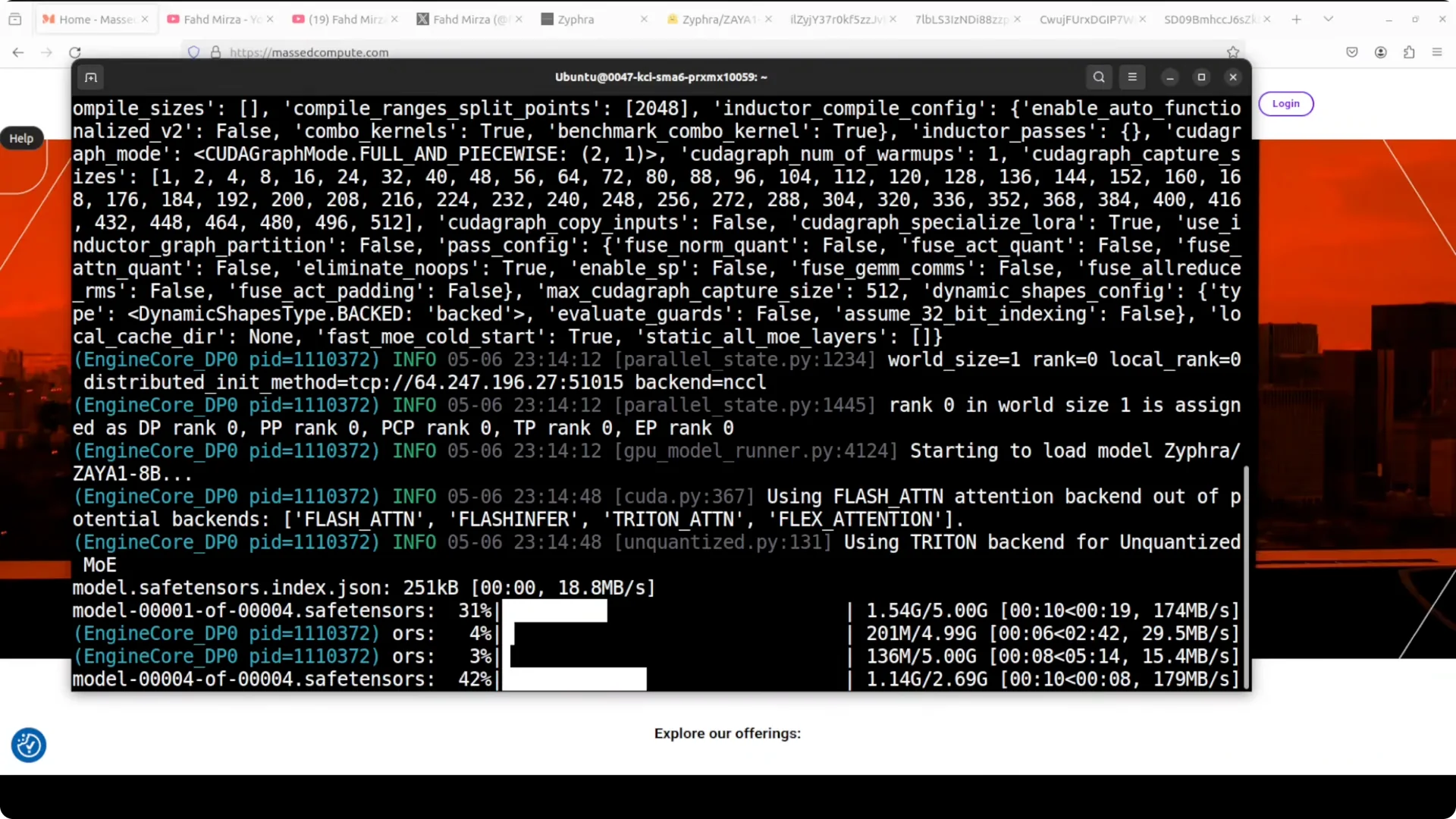
I used vLLM to serve Zyphra’s Zaya1 model locally.
The first run downloaded four shards and then served the model for inference.
I interacted through Open WebUI once the server was up.
Parser and reasoning mode
Zyphra includes its own parser, but the setup still uses the Qwen 3 reasoning parser for chain-of-thought style prompting. That pairing is what the team leans on for math and logic depth.
The post-training pipeline emphasizes math, puzzle-solving, and coding with heavy RL phases.
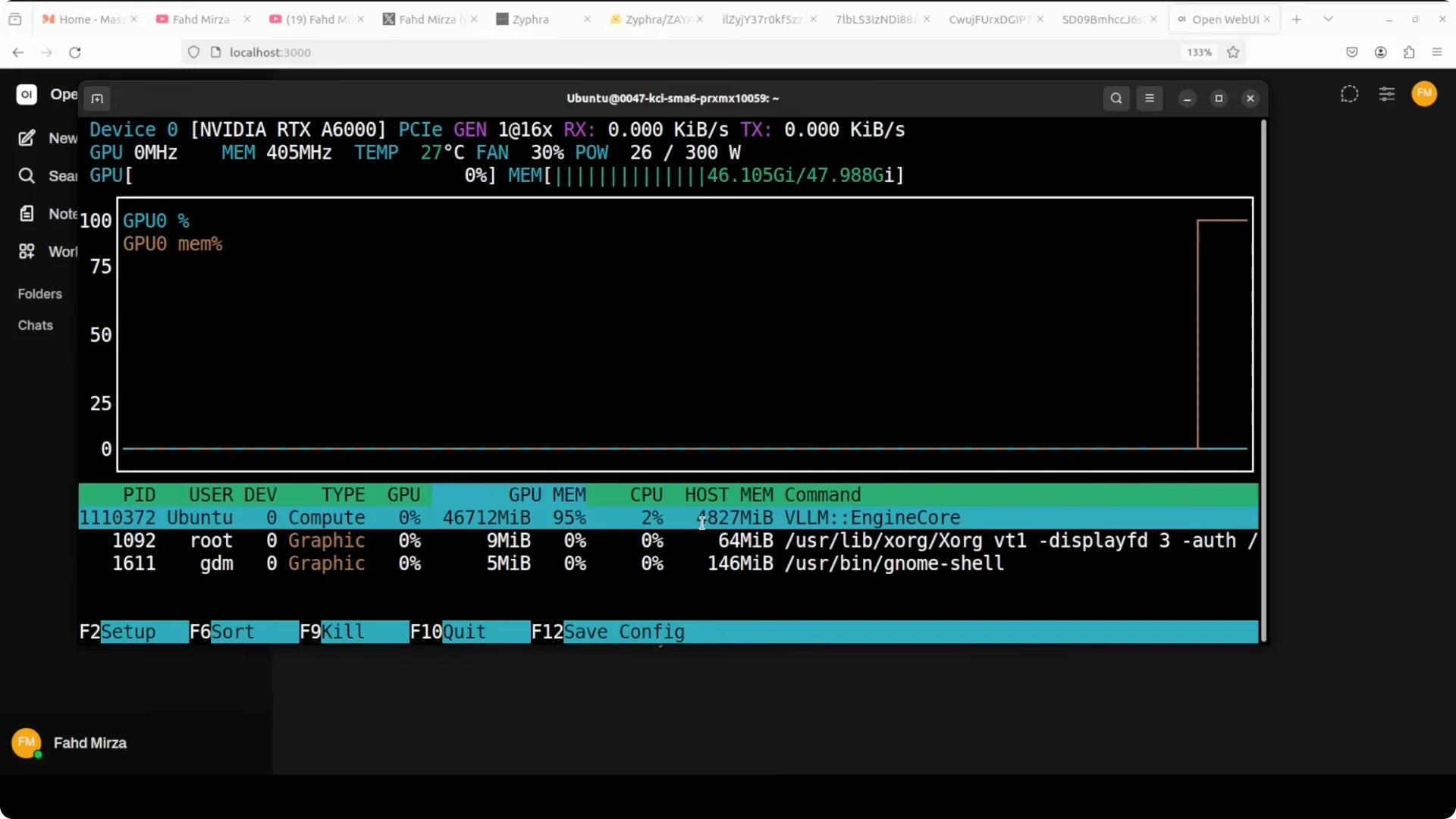
Hardware and VRAM notes
This run used Ubuntu with an NVIDIA RTX 6000 48 GB. VRAM consumption sat a bit over 46 GB, around 47 GB once loaded.
Expect high memory use for fast local serving at full precision.
Step-by-step to replicate my flow
1. Install vLLM, then serve the Zaya1 8B weights and wait while all shards download.
2. Open your WebUI front end once the model is live and confirm memory and token throughput.
3. Run prompts that combine multi-step math, logic, and coding to see where it shines and where it slips.
Read More: install Claude Code in Antigravity
Math stress test
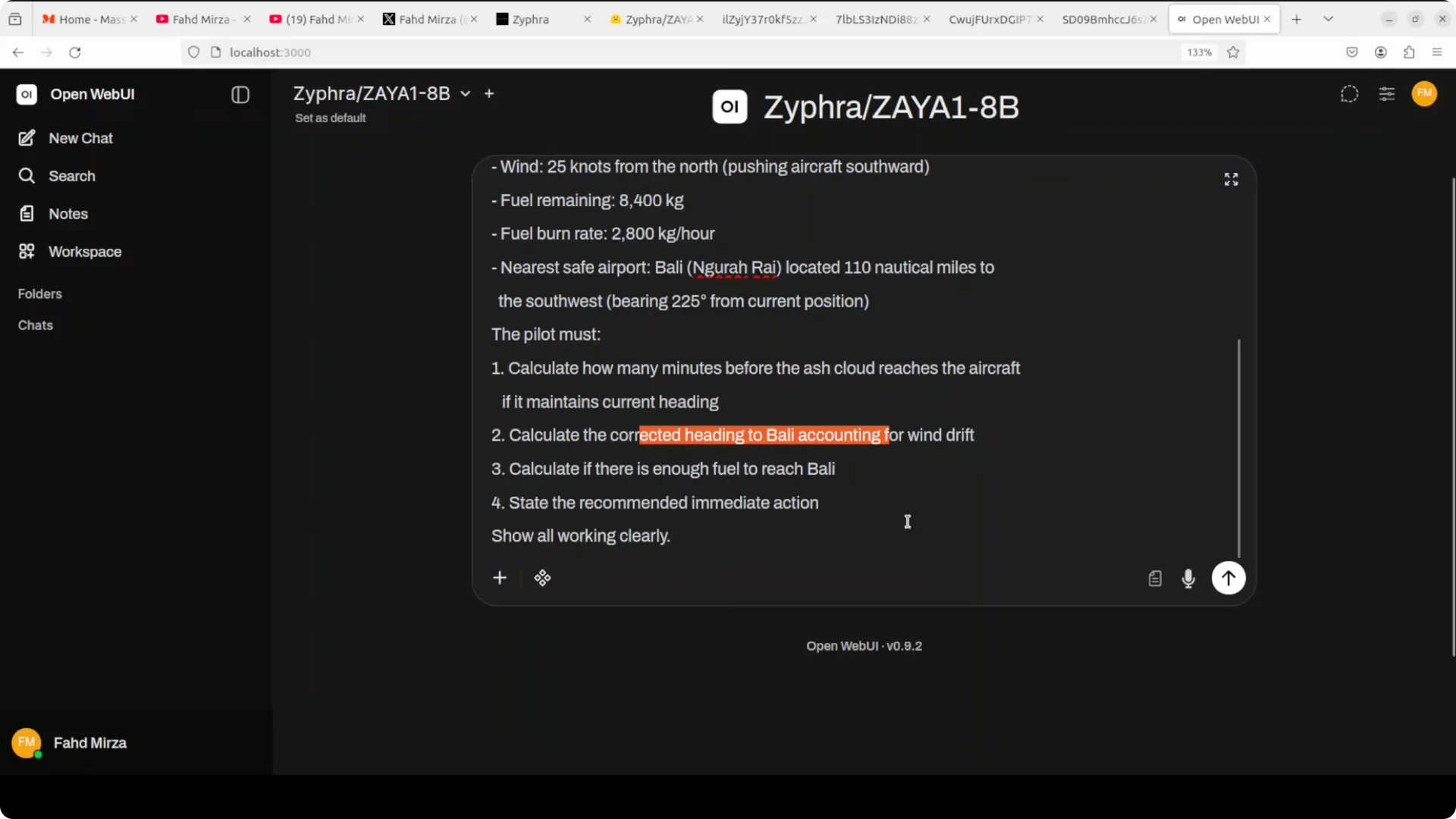
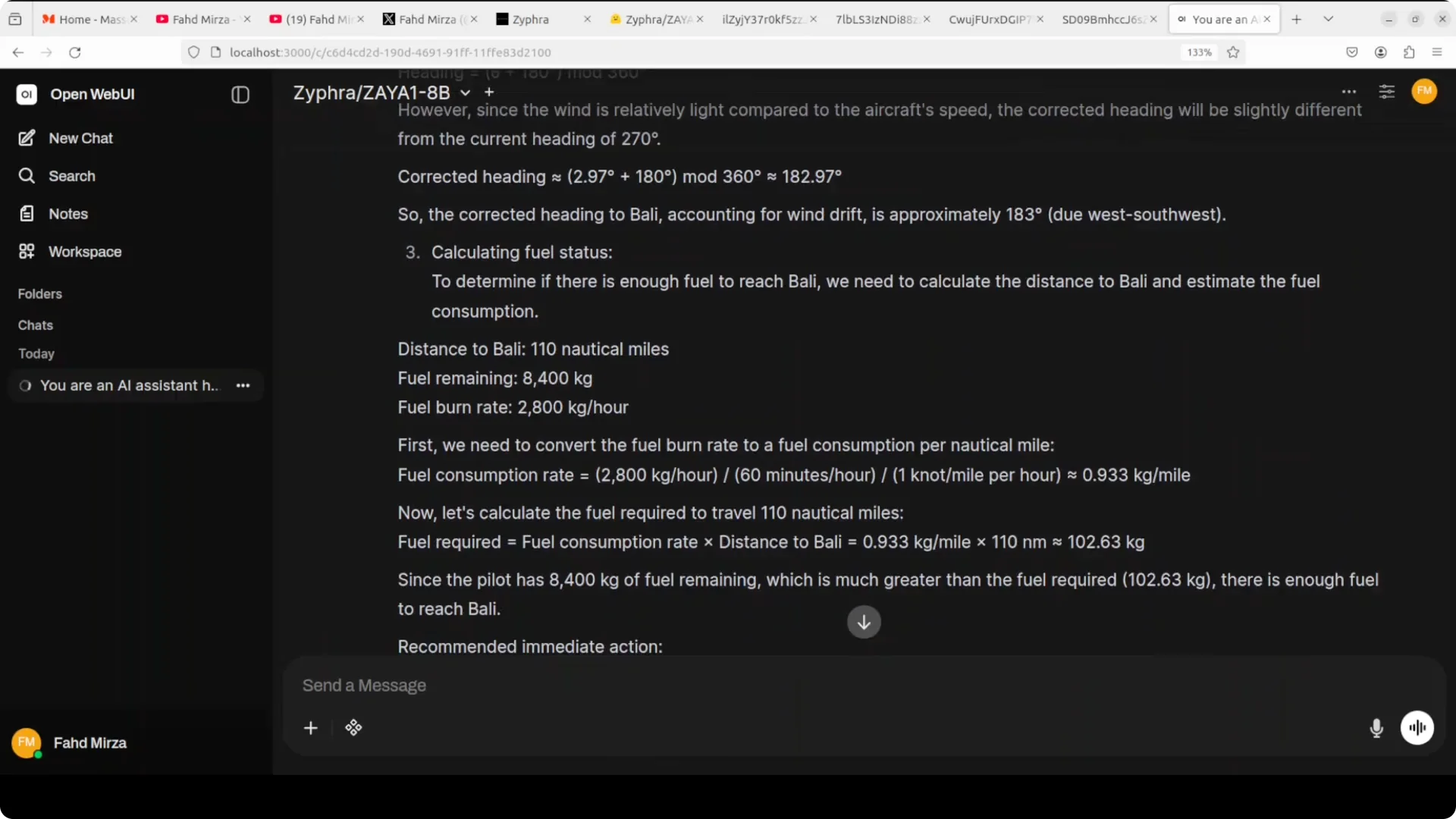
I asked the model to act as an AI assistant helping a pilot in an emergency over East Java near Mount Semeru at FL350, with a radially expanding ash cloud at 35 knots and a specified position due east of the volcano.
The task asked for time to ash impact, the correct heading to Bali, fuel sufficiency, and an immediate action plan under wind and performance constraints.
The point was to test geometry, wind drift, fuel burn, and timing together rather than formula fill-in.
Results and critique
It handled fuel calculation and wind vector math correctly and judged the ash cloud timing at about 80 minutes, which is more accurate because the aircraft is essentially stationary relative to the ash rather than closing at a combined speed.
The notable error was the outbound course, where it returned about 183 degrees instead of about 228 degrees to Bali.
Strong reasoning speed and structure, but a heading error is a no-go in aviation.
Coding system build
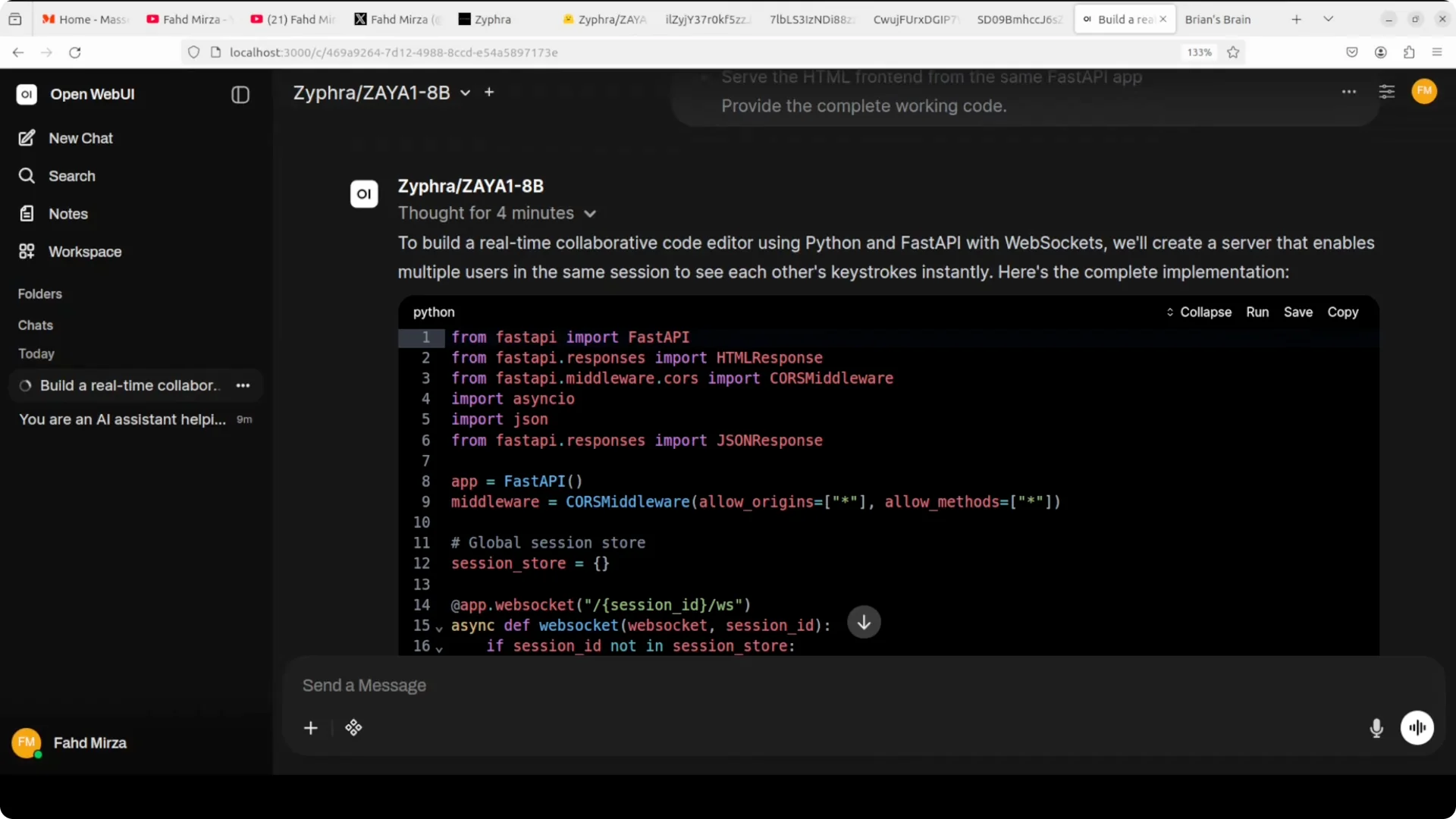
I then prompted it to build a realtime collaborative code editor using Python and FastAPI with WebSocket server sections, state management, front-end integration, and real-time broadcast.
It generated the full solution in about four minutes, listed local dependencies, and described how to run the app with uvicorn and open different session IDs.
I copied the output to app.py, ran the server, and reached the UI as instructed.
Realtime behavior and isolation
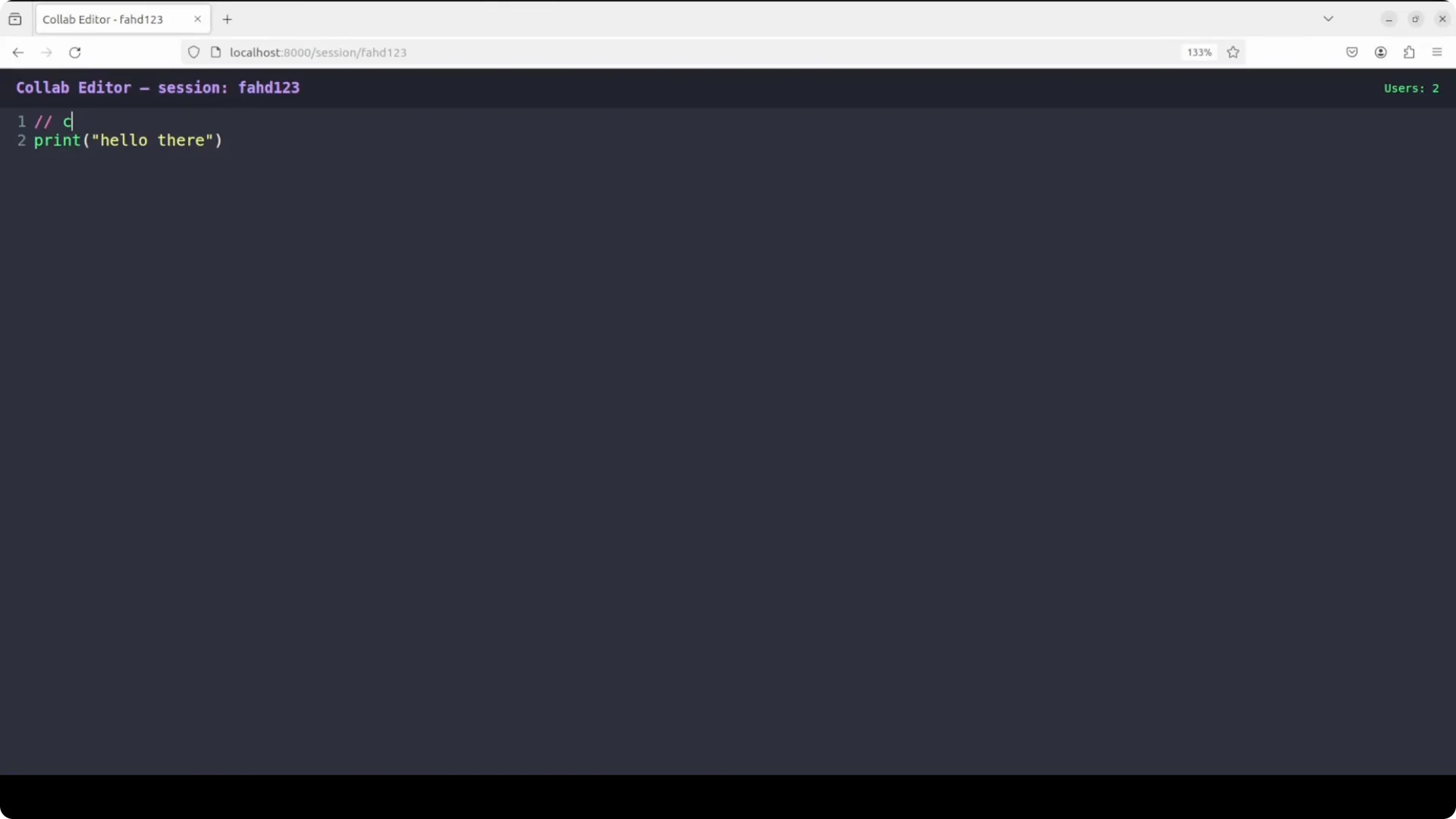
I opened two separate browser windows to simulate two users in the same session ID.
Typing in one window synced instantly to the other over WebSockets without refresh.
I then created a different session ID to confirm isolation and both sessions stayed independent, which means the state and broadcast logic were wired correctly.
Read More: add text-to-speech to your app
Takeaways
Zaya1 8B is a compact MoE model trained fully on AMD that competes with much larger systems on tough math and logic. The architecture choices and Marovian RSA cycles explain its hard-task gains, and local serving via vLLM was straightforward, though memory hungry.
In practice it thinks fast and codes well, but you should expect occasional directional slips on navigation-type prompts.
Final thoughts
Zyphra set a clear target to squeeze more from fewer active parameters and Zaya1 8B largely hits that target. The math and coding trials show strong signal with one important heading miss to watch for. If you can budget the VRAM, it is a compelling small model to test for reasoning and code-heavy workloads.