The official DFlash drafter from Z-Lab is out, paired with the Gemma 26B A4B MoE model from Google, and it delivers a big boost in throughput without hurting quality. On an H100 80 GB, I saw 222.3 tokens per second with a mean acceptance length of 7.8 and roughly a 3.4 times speedup over autoregressive decoding.
The drafter proposes blocks of tokens in parallel, the main model verifies them in one shot, and the output quality stays the same.
You can run it locally with vLLM by serving two models together: Gemma 26B A4B as the main model and the Z-Lab DFlash drafter proposing 15 tokens per step.
Set the attention backend to Triton for the main model, use FlashAttention for the drafter, and configure max batched tokens around 32K.
Access is gated on Hugging Face and the license is Apache 2.
What was released
Z-Lab at UC San Diego released their own official drafter model for Gemma 26B A4B. The pairing is interesting because the main model is a mixture of experts with about 26B parameters in total but only 4B active per token.
That means it runs at roughly the speed of a 4B model while keeping the capability of something much larger. Add DFlash speculative decoding on top and the numbers get very interesting.
I have been covering DFlash for a few weeks, running it locally on consumer GPUs and testing ports and speculative setups across different model sizes. Today I pushed it with Z-Lab’s own official drafter on the H100 and measured speed in a real task.
How DFlash works?
Normal inference generates one token at a time and every word requires a full trip through the whole model.
DFlash brings in a tiny drafter that looks at the hidden states inside the big model and proposes an entire block of tokens in one forward pass.
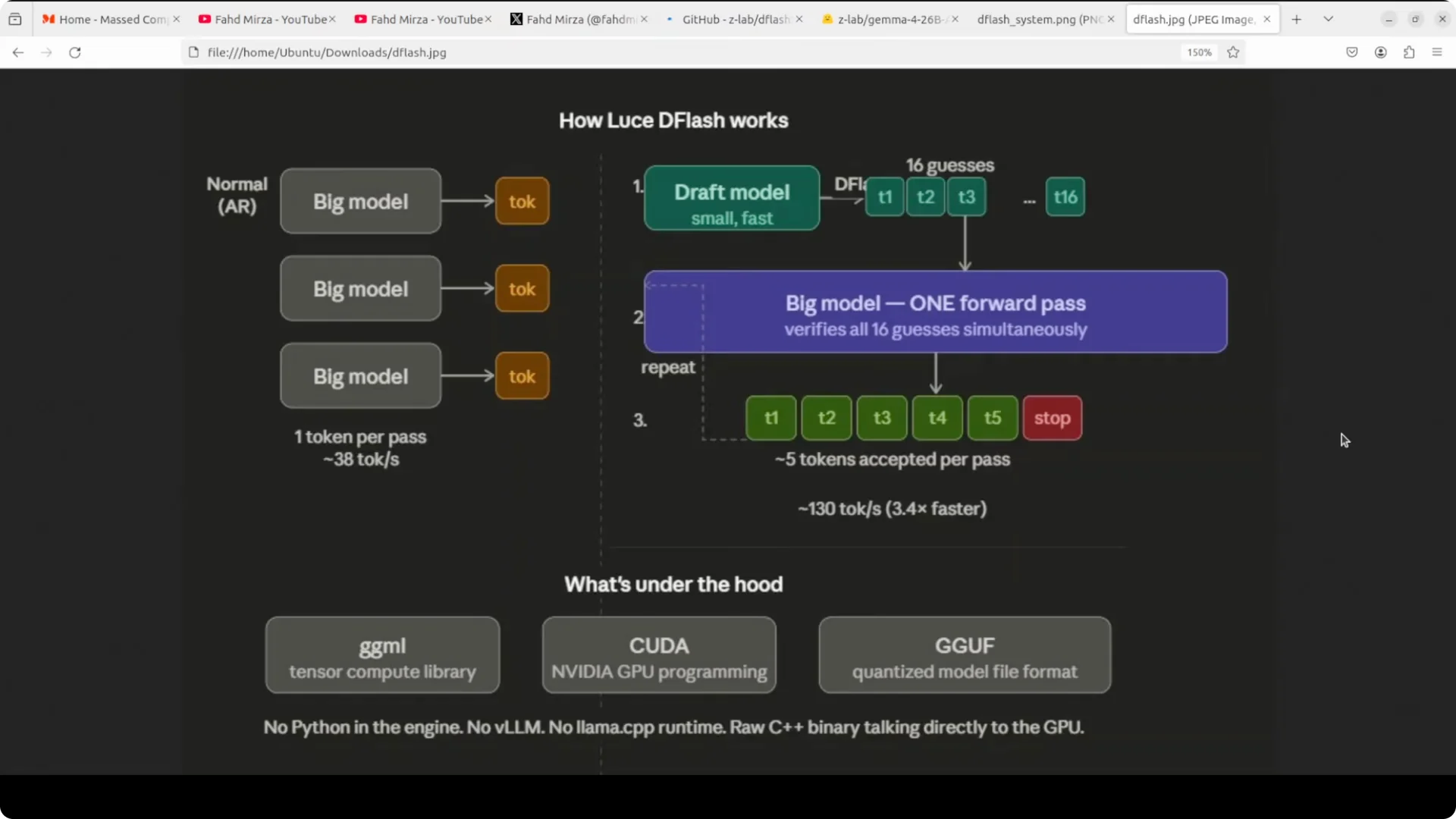
The big model then verifies all of them at once.
Same output quality, dramatically more tokens per second.
The keyword here is block diffusion where all draft tokens are proposed in parallel, not sequentially like standard speculative decoding.
Read More: Best Way To Use Claude Code
Hardware and tools
I am running this on Ubuntu with a single Nvidia H100 80 GB GPU. The tool I am using to serve and test the model is vLLM.
You need to install vLLM from a branch that includes DFlash support.
It should be merged into main vLLM soon.
Serve the model
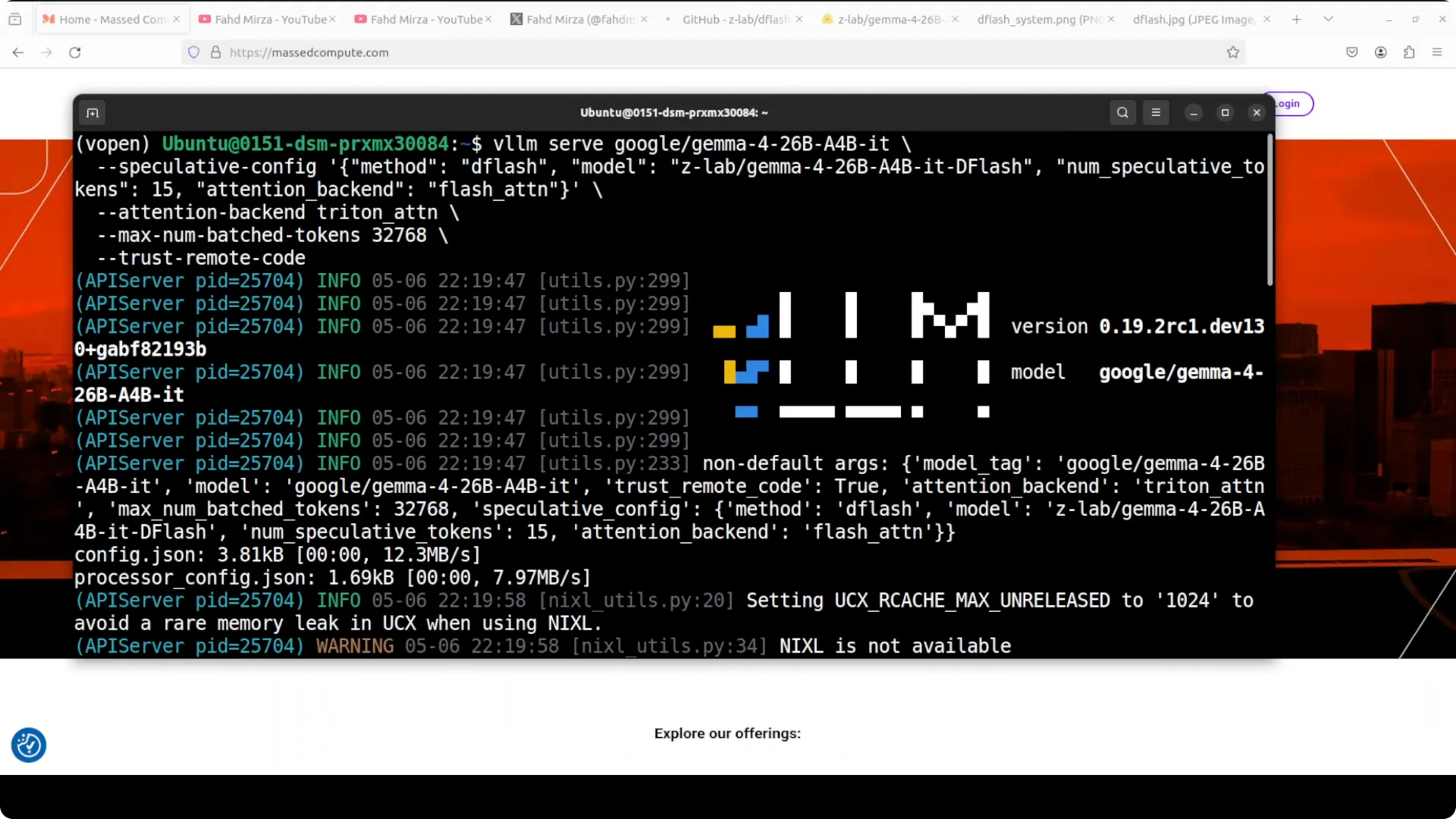
The first time you start the vLLM server it will download the model.
I serve two models together so they work side by side.
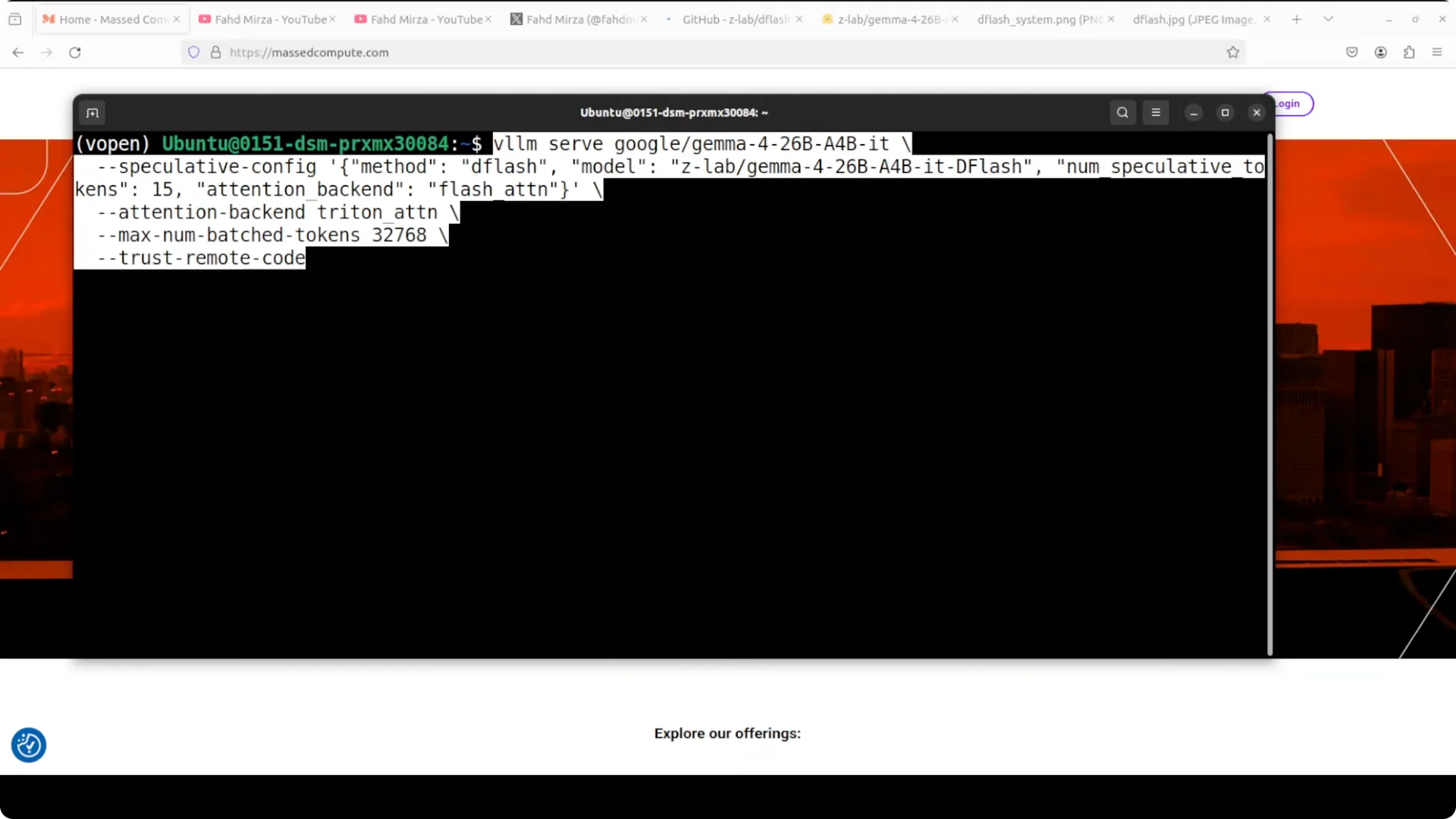
Gemma 26B A4B is the main model that produces the final answer.
The Z-Lab DFlash drafter sits alongside it, proposing 15 tokens per step for the big model to verify in one shot.
Configuration highlights
The attention backend is set to Triton for the main model.
Triton is Nvidia’s open source GPU programming language that lets you write highly optimized CUDA kernels without raw CUDA.
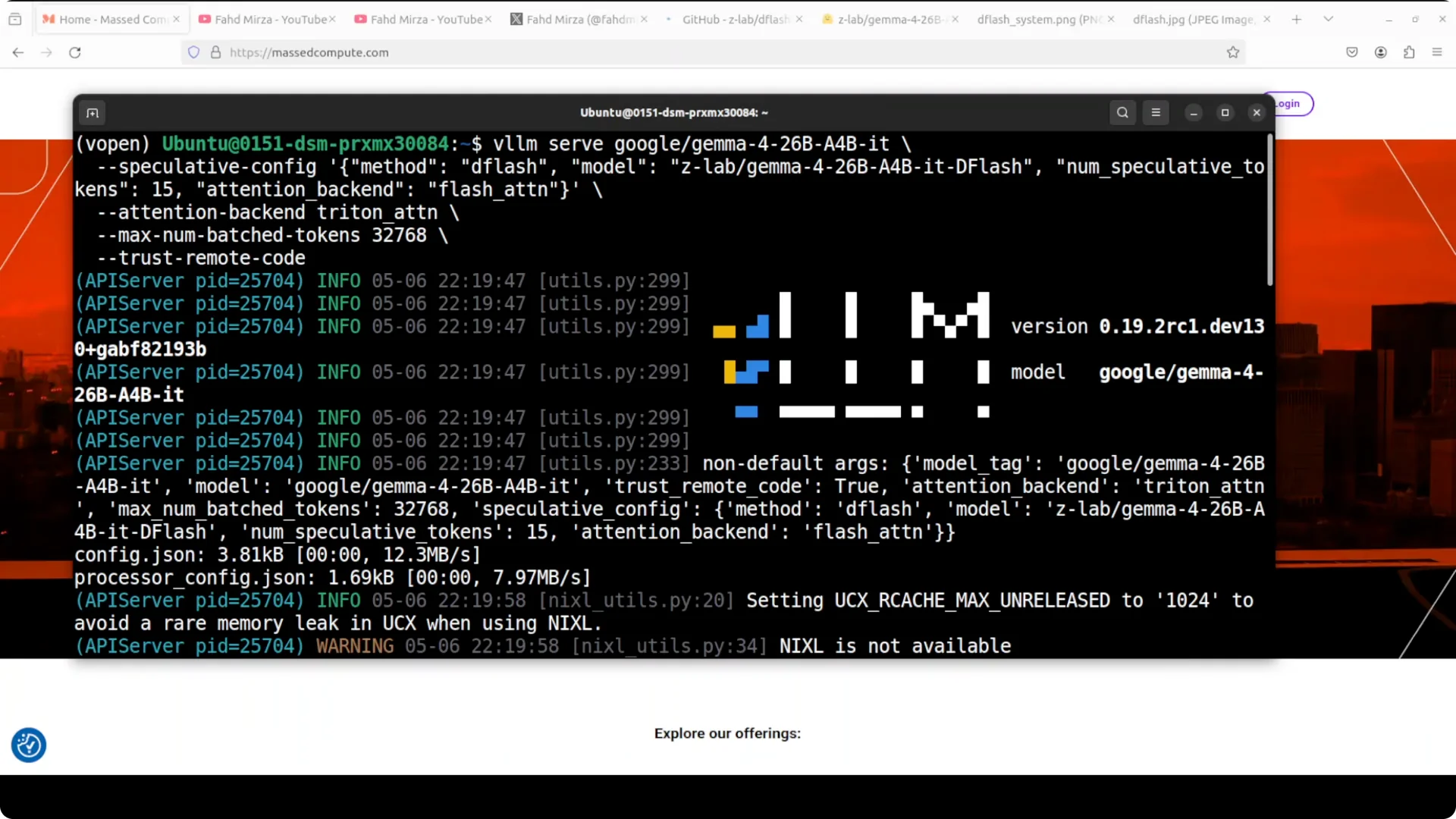
The drafter uses FlashAttention which is a memory efficient attention algorithm tuned for the smaller drafter forward pass.
I set max batched tokens to around 32K which controls how many tokens vLLM processes in a single forward pass across all requests combined.
If you are thinking about orchestrating multiple workers or models around this stack, see concepts similar to an agent manager for coordination ideas.
Read More: Agent Manager Antigravity
Access and license
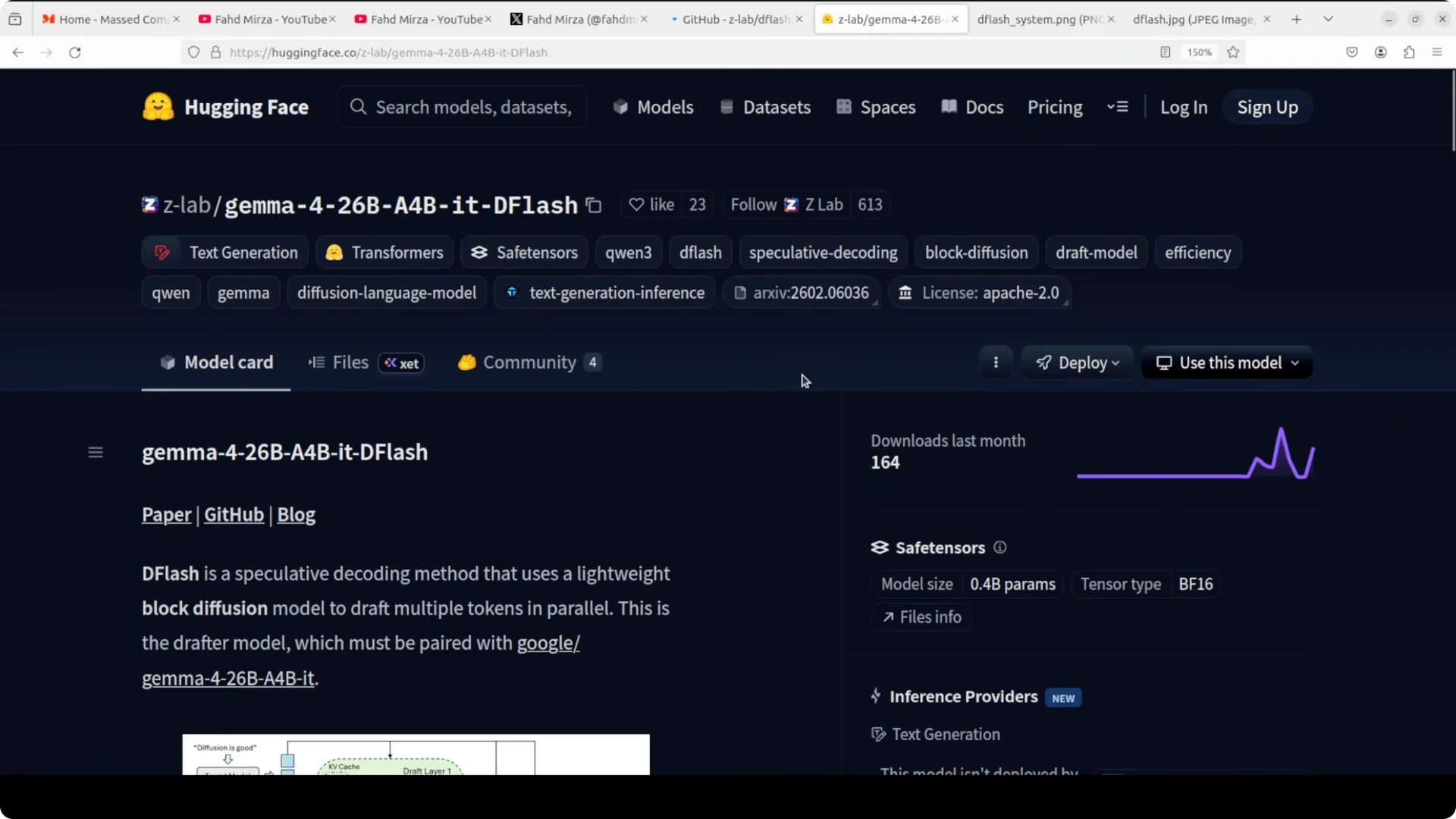
This is a gated model, so you need to accept terms on Hugging Face to get access. The license is Apache 2, which is a good sign for usage.
Read More: Claude Code Vs Antigravity
Run a real test
To measure speed, I send a complex drone swarm animation prompt to Gemma running with DFlash.
The task is to generate a full HTML file for a working animation.
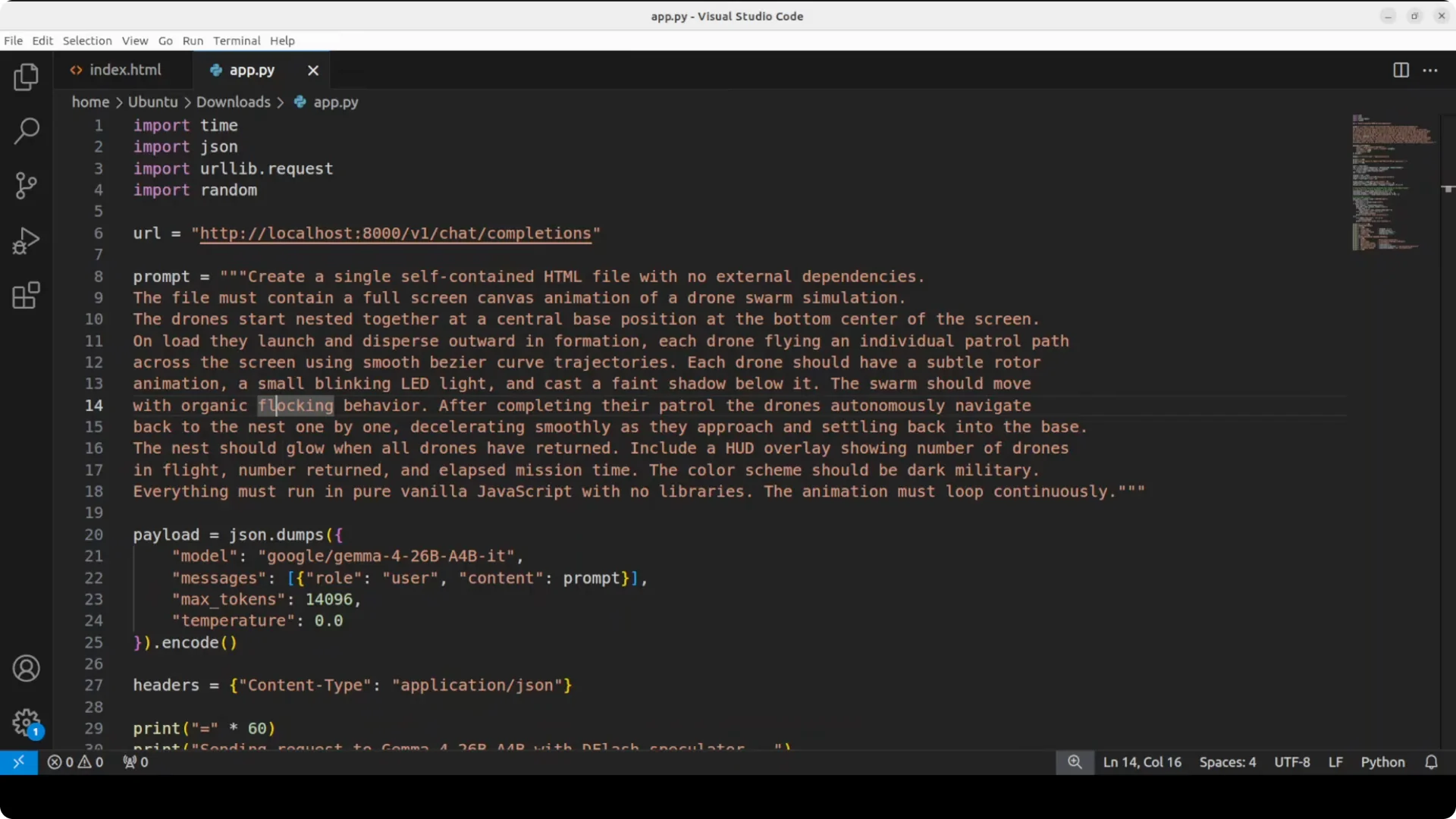
The output is saved directly to disk as index.html so I can open it in the browser.
The goal here is to test throughput gains, not model creativity.
Results:
All tokens were generated in just 18 seconds at 222.3 tokens per second with a mean acceptance length around 7.8.
In simple words, the drafter correctly guessed nearly eight tokens per step on average before the big model needed to step in.
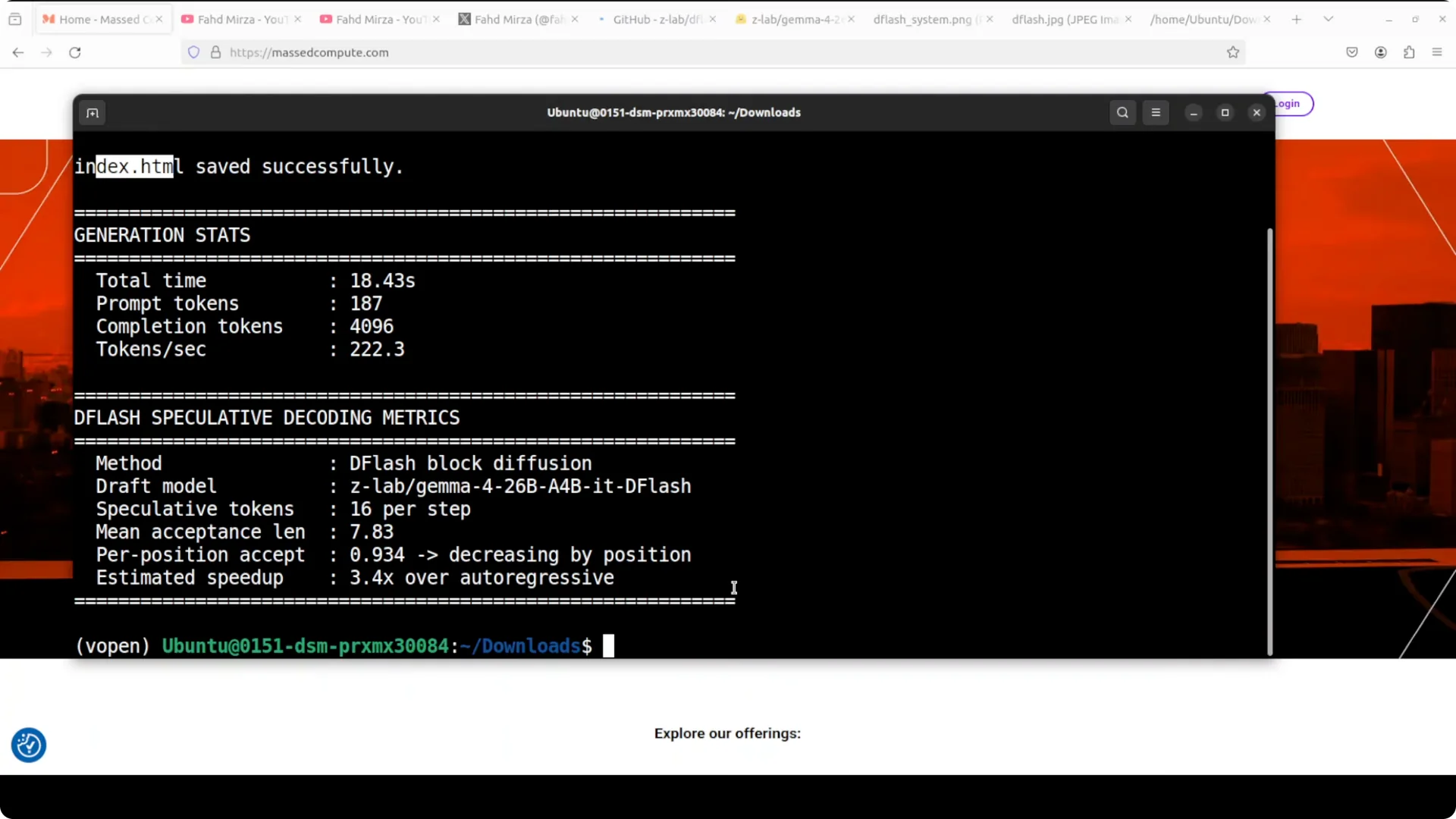
That is about 3.4 times faster than plain autoregressive decoding and is consistent with what Z-Lab published in their benchmarks.
The swarm animation works and the stats line up with what the diagram suggests.
Support and variants
vLLM support is already pretty good with this setup. There is also an SGLang implementation if you prefer that stack.
Z-Lab has another drafter variant on their Hugging Face card. The ecosystem is moving fast and the numbers look real.
Final thoughts
The algorithm works as described, and the official drafter pushes DFlash past a proof of concept into something you can run locally. Block diffusion with a small drafter and a strong MoE main model delivers real speed without giving up quality.
I will keep testing as updates land in vLLM and as new drafter variants appear.